
![]()
2026 Easy Success Appian ACD-301 Exam in First Try
Best ACD-301 Exam Dumps for the Preparation of Latest Exam Questions
NEW QUESTION # 14
You are reviewing the Engine Performance Logs in Production for a single application that has been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs. You also notice unattended process activities, including timer events and sending notification emails, are taking far longer to execute than normal.The client increased the number of CPU cores prior to the application going live.What is the next recommendation?
- A. Add more engine replicas.
- B. Add execution and analytics shards
- C. Add more application servers.
- D. Optimize slow-performing user interfaces.
Answer: A
NEW QUESTION # 15
Your application contains a process model that is scheduled to run daily at a certain time, which kicks off a user input task to a specified user on the 1st time zone for morning data collection. The time zone is set to the (default) pm!timezone. In this situation, what does the pm!timezone reflect?
- A. The default time zone for the environment as specified in the Administration Console.
- B. The time zone of the server where Appian is installed.
- C. The time zone of the user who is completing the input task.
- D. The time zone of the user who most recently published the process model.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
In Appian, the pm!timezone variable is a process variable automatically available in process models, reflecting the time zone context for scheduled or time-based operations. Understanding its behavior is critical for scheduling tasks accurately, especially in scenarios like this where a process runs daily and assigns a user input task.
Option C (The default time zone for the environment as specified in the Administration Console):
This is the correct answer. Per Appian's Process Model documentation, when a process model uses pm!timezone and no custom time zone is explicitly set, it defaults to the environment's time zone configured in the Administration Console (under System > Time Zone settings). For scheduled processes, such as one running "daily at a certain time," Appian uses this default time zone to determine when the process triggers. In this case, the task assignment occurs based on the schedule, and pm!timezone reflects the environment's setting, not the user's location.
Option A (The time zone of the server where Appian is installed): This is incorrect. While the server's time zone might influence underlying system operations, Appian abstracts this through the Administration Console's time zone setting. The pm!timezone variable aligns with the configured environment time zone, not the raw server setting.
Option B (The time zone of the user who most recently published the process model): This is irrelevant. Publishing a process model does not tie pm!timezone to the publisher's time zone. Appian's scheduling is system-driven, not user-driven in this context.
Option D (The time zone of the user who is completing the input task): This is also incorrect. While Appian can adjust task display times in the user interface to the assigned user's time zone (based on their profile settings), the pm!timezone in the process model reflects the environment's default time zone for scheduling purposes, not the assignee's.
For example, if the Administration Console is set to EST (Eastern Standard Time), the process will trigger daily at the specified time in EST, regardless of the assigned user's location. The "1st time zone" phrasing in the question appears to be a typo or miscommunication, but it doesn't change the fact that pm!timezone defaults to the environment setting.
NEW QUESTION # 16
You are in a backlog refinement meeting with the development team and the product owner. You review a story for an integration involving a third-party system. A payload will be sent from the Appian system through the integration to the third-party system. The story is 21 points on a Fibonacci scale and requires development from your Appian team as well as technical resources from the third-party system. This item is crucial to your project's success. What are the two recommended steps to ensure this story can be developed effectively?
- A. Identify subject matter experts (SMEs) to perform user acceptance testing (UAT).
- B. Break down the item into smaller stories.
- C. Maintain a communication schedule with the third-party resources.
- D. Acquire testing steps from QA resources.
Answer: B,C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
This question involves a complex integration story rated at 21 points on the Fibonacci scale, indicating significant complexity and effort. Appian Lead Developer best practices emphasize effective collaboration, risk mitigation, and manageable development scopes for such scenarios. The two most critical steps are:
Option C (Maintain a communication schedule with the third-party resources):
Integrations with third-party systems require close coordination, as Appian developers depend on external teams for endpoint specifications, payload formats, authentication details, and testing support. Establishing a regular communication schedule ensures alignment on requirements, timelines, and issue resolution. Appian's Integration Best Practices documentation highlights the importance of proactive communication with external stakeholders to prevent delays and misunderstandings, especially for critical project components.
Option D (Break down the item into smaller stories):
A 21-point story is considered large by Agile standards (Fibonacci scale typically flags anything above 13 as complex). Appian's Agile Development Guide recommends decomposing large stories into smaller, independently deliverable pieces to reduce risk, improve testability, and enable iterative progress. For example, the integration could be split into tasks like designing the payload structure, building the integration object, and testing the connection-each manageable within a sprint. This approach aligns with the principle of delivering value incrementally while maintaining quality.
Option A (Acquire testing steps from QA resources): While QA involvement is valuable, this step is more relevant during the testing phase rather than backlog refinement or development preparation. It's not a primary step for ensuring effective development of the story.
Option B (Identify SMEs for UAT): User acceptance testing occurs after development, during the validation phase. Identifying SMEs is important but not a key step in ensuring the story is developed effectively during the refinement and coding stages.
By choosing C and D, you address both the external dependency (third-party coordination) and internal complexity (story size), ensuring a smoother development process for this critical integration.
NEW QUESTION # 17
You are required to create an integration from your Appian Cloud instance to an application hosted within a customer's self-managed environment.
The customer's IT team has provided you with a REST API endpoint to test with: https://internal.network/api/api/ping.
Which recommendation should you make to progress this integration?
- A. Add Appian Cloud's IP address ranges to the customer network's allowed IP listing.
- B. Expose the API as a SOAP-based web service.
- C. Set up a VPN tunnel.
- D. Deploy the API/service into Appian Cloud.
Answer: C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating an Appian Cloud instance with a customer's self-managed (on-premises) environment requires addressing network connectivity, security, and Appian's cloud architecture constraints. The provided endpoint (https://internal.network/api/api/ping) is a REST API on an internal network, inaccessible directly from Appian Cloud due to firewall restrictions and lack of public exposure. Let's evaluate each option:
A . Expose the API as a SOAP-based web service:
Converting the REST API to SOAP isn't a practical recommendation. The customer has provided a REST endpoint, and Appian fully supports REST integrations via Connected Systems and Integration objects. Changing the API to SOAP adds unnecessary complexity, development effort, and risks for the customer, with no benefit to Appian's integration capabilities. Appian's documentation emphasizes using the API's native format (REST here), making this irrelevant.
B . Deploy the API/service into Appian Cloud:
Deploying the customer's API into Appian Cloud is infeasible. Appian Cloud is a managed PaaS environment, not designed to host customer applications or APIs. The API resides in the customer's self-managed environment, and moving it would require significant architectural changes, violating security and operational boundaries. Appian's integration strategy focuses on connecting to external systems, not hosting them, ruling this out.
C . Add Appian Cloud's IP address ranges to the customer network's allowed IP listing:
This approach involves whitelisting Appian Cloud's IP ranges (available in Appian documentation) in the customer's firewall to allow direct HTTP/HTTPS requests. However, Appian Cloud's IPs are dynamic and shared across tenants, making this unreliable for long-term integrations-changes in IP ranges could break connectivity. Appian's best practices discourage relying on IP whitelisting for cloud-to-on-premises integrations due to this limitation, favoring secure tunnels instead.
D . Set up a VPN tunnel:
This is the correct recommendation. A Virtual Private Network (VPN) tunnel establishes a secure, encrypted connection between Appian Cloud and the customer's self-managed network, allowing Appian to access the internal REST API (https://internal.network/api/api/ping). Appian supports VPNs for cloud-to-on-premises integrations, and this approach ensures reliability, security, and compliance with network policies. The customer's IT team can configure the VPN, and Appian's documentation recommends this for such scenarios, especially when dealing with internal endpoints.
Conclusion: Setting up a VPN tunnel (D) is the best recommendation. It enables secure, reliable connectivity from Appian Cloud to the customer's internal API, aligning with Appian's integration best practices for cloud-to-on-premises scenarios.
Appian Documentation: "Integrating Appian Cloud with On-Premises Systems" (VPN and Network Configuration).
Appian Lead Developer Certification: Integration Module (Cloud-to-On-Premises Connectivity).
Appian Best Practices: "Securing Integrations with Legacy Systems" (VPN Recommendations).
NEW QUESTION # 18
You are designing a process that is anticipated to be executed multiple times a day. This process retrieves data from an external system and then calls various utility processes as needed. The main process will not use the results of the utility processes, and there are no user forms anywhere.
Which design choice should be used to start the utility processes and minimize the load on the execution engines?
- A. Start the utility processes via a subprocess asynchronously.
- B. Start the utility processes via a subprocess synchronously.
- C. Use the Start Process Smart Service to start the utility processes.
- D. Use Process Messaging to start the utility process.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a process that executes frequently (multiple times a day) and calls utility processes without using their results requires optimizing performance and minimizing load on Appian's execution engines. The absence of user forms indicates a backend process, so user experience isn't a concern-only engine efficiency matters. Let's evaluate each option:
A . Use the Start Process Smart Service to start the utility processes:
The Start Process Smart Service launches a new process instance independently, creating a separate process in the Work Queue. While functional, it increases engine load because each utility process runs as a distinct instance, consuming engine resources and potentially clogging the Java Work Queue, especially with frequent executions. Appian's performance guidelines discourage unnecessary separate process instances for utility tasks, favoring integrated subprocesses, making this less optimal.
B . Start the utility processes via a subprocess synchronously:
Synchronous subprocesses (e.g., a!startProcess with isAsync: false) execute within the main process flow, blocking until completion. For utility processes not used by the main process, this creates unnecessary delays, increasing execution time and engine load. With frequent daily executions, synchronous subprocesses could strain engines, especially if utility processes are slow or numerous. Appian's documentation recommends asynchronous execution for non-dependent, non-blocking tasks, ruling this out.
C . Use Process Messaging to start the utility process:
Process Messaging (e.g., sendMessage() in Appian) is used for inter-process communication, not for starting processes. It's designed to pass data between running processes, not initiate new ones. Attempting to use it for starting utility processes would require additional setup (e.g., a listening process) and isn't a standard or efficient method. Appian's messaging features are for coordination, not process initiation, making this inappropriate.
D . Start the utility processes via a subprocess asynchronously:
This is the best choice. Asynchronous subprocesses (e.g., a!startProcess with isAsync: true) execute independently of the main process, offloading work to the engine without blocking or delaying the parent process. Since the main process doesn't use the utility process results and there are no user forms, asynchronous execution minimizes engine load by distributing tasks across time, reducing Work Queue pressure during frequent executions. Appian's performance best practices recommend asynchronous subprocesses for non-dependent, utility tasks to optimize engine utilization, making this ideal for minimizing load.
Conclusion: Starting the utility processes via a subprocess asynchronously (D) minimizes engine load by allowing independent execution without blocking the main process, aligning with Appian's performance optimization strategies for frequent, backend processes.
Appian Documentation: "Process Model Performance" (Synchronous vs. Asynchronous Subprocesses).
Appian Lead Developer Certification: Process Design Module (Optimizing Engine Load).
Appian Best Practices: "Designing Efficient Utility Processes" (Asynchronous Execution).
NEW QUESTION # 19
A customer wants to integrate a CSV file once a day into their Appian application, sent every night at 1:00 AM. The file contains hundreds of thousands of items to be used daily by users as soon as their workday starts at 8:00 AM. Considering the high volume of data to manipulate and the nature of the operation, what is the best technical option to process the requirement?
- A. Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data.
- B. Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration.
- C. Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures.
- D. Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, handling a daily CSV integration with hundreds of thousands of items requires a solution that balances performance, scalability, and Appian's architectural strengths. The timing (1:00 AM integration, 8:00 AM availability) and data volume necessitate efficient processing and minimal runtime overhead. Let's evaluate each option based on Appian's official documentation and best practices:
A . Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements:
This approach involves parsing the CSV in a process model and using a looping mechanism (e.g., a subprocess or script task with fn!forEach) to process each item. While Appian process models are excellent for orchestrating workflows, they are not optimized for high-volume data processing. Looping over hundreds of thousands of records would strain the process engine, leading to timeouts, memory issues, or slow execution-potentially missing the 8:00 AM deadline. Appian's documentation warns against using process models for bulk data operations, recommending database-level processing instead. This is not a viable solution.
B . Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data:
This suggests loading the CSV into a table and creating an optimized database view (e.g., with indices and joins) for user queries via a!queryEntity. While this improves read performance for users at 8:00 AM, it doesn't address the integration process itself. The question focuses on processing the CSV ("manipulate" and "operation"), not just querying. Building a view assumes the data is already loaded and transformed, leaving the heavy lifting of integration unaddressed. This option is incomplete and misaligned with the requirement's focus on processing efficiency.
C . Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration:
This is the best choice. Stored procedures, executed in the database, are designed for high-volume data manipulation (e.g., parsing CSV, transforming data, and applying business logic). In this scenario, you can configure an Appian process model to trigger at 1:00 AM (using a timer event) after the CSV is received (e.g., via FTP or Appian's File System utilities), then call a stored procedure via the "Execute Stored Procedure" smart service. The stored procedure can efficiently bulk-load the CSV (e.g., using SQL's BULK INSERT or equivalent), process the data, and update tables-all within the database's optimized environment. This ensures completion by 8:00 AM and aligns with Appian's recommendation to offload complex, large-scale data operations to the database layer, maintaining Appian as the orchestration layer.
D . Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures:
This hybrid approach splits the workload: simple tasks (e.g., validation) in a process model, and complex tasks (e.g., transformations) in stored procedures. While this leverages Appian's strengths (orchestration) and database efficiency, it adds unnecessary complexity. Managing two layers of processing increases maintenance overhead and risks partial failures (e.g., process model timeouts before stored procedures run). Appian's best practices favor a single, cohesive approach for bulk data integration, making this less efficient than a pure stored procedure solution (C).
Conclusion: Creating a set of stored procedures (C) is the best option. It leverages the database's native capabilities to handle the high volume and complexity of the CSV integration, ensuring fast, reliable processing between 1:00 AM and 8:00 AM. Appian orchestrates the trigger and integration (e.g., via a process model), while the stored procedure performs the heavy lifting-aligning with Appian's performance guidelines for large-scale data operations.
Appian Documentation: "Execute Stored Procedure Smart Service" (Process Modeling > Smart Services).
Appian Lead Developer Certification: Data Integration Module (Handling Large Data Volumes).
Appian Best Practices: "Performance Considerations for Data Integration" (Database vs. Process Model Processing).
NEW QUESTION # 20
You are planning a strategy around data volume testing for an Appian application that queries and writes to a MySQL database. You have administrator access to the Appian application and to the database. What are two key considerations when designing a data volume testing strategy?
- A. Data model changes must wait until towards the end of the project.
- B. The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation.
- C. Large datasets must be loaded via Appian processes.
- D. Data from previous tests needs to remain in the testing environment prior to loading prepopulated data.
- E. Testing with the correct amount of data should be in the definition of done as part of each sprint.
Answer: B,E
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Data volume testing ensures an Appian application performs efficiently under realistic data loads, especially when interacting with external databases like MySQL. As an Appian Lead Developer with administrative access, the focus is on scalability, performance, and iterative validation. The two key considerations are:
Option C (The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation):
Determining the appropriate data volume is critical to simulate real-world usage. Appian's Performance Testing Best Practices recommend collaborating with stakeholders (e.g., project sponsors, business analysts) to define expected data sizes based on production scenarios. This ensures the test reflects actual requirements-like peak transaction volumes or record counts-rather than arbitrary guesses. For example, if the application will handle 1 million records in production, stakeholders must specify this to guide test data preparation.
Option D (Testing with the correct amount of data should be in the definition of done as part of each sprint):
Appian's Agile Development Guide emphasizes incorporating performance testing (including data volume) into the Definition of Done (DoD) for each sprint. This ensures that features are validated under realistic conditions iteratively, preventing late-stage performance issues. With admin access, you can query/write to MySQL and assess query performance or write latency with the specified data volume, aligning with Appian's recommendation to "test early and often." Option A (Data from previous tests needs to remain in the testing environment prior to loading prepopulated data): This is impractical and risky. Retaining old test data can skew results, introduce inconsistencies, or violate data integrity (e.g., duplicate keys in MySQL). Best practices advocate for a clean, controlled environment with fresh, prepopulated data per test cycle.
Option B (Large datasets must be loaded via Appian processes): While Appian processes can load data, this is not a requirement. With database admin access, you can use SQL scripts or tools like MySQL Workbench for faster, more efficient data population, bypassing Appian process overhead. Appian documentation notes this as a preferred method for large datasets.
Option E (Data model changes must wait until towards the end of the project): Delaying data model changes contradicts Agile principles and Appian's iterative design approach. Changes should occur as needed throughout development to adapt to testing insights, not be deferred.
NEW QUESTION # 21
You are running an inspection as part of the first deployment process from TEST to PROD. You receive a notice that one of your objects will not deploy because it is dependent on an object from an application owned by a separate team.
What should be your next step?
- A. Halt the production deployment and contact the other team for guidance on promoting the object to PROD.
- B. Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD.
- C. Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk.
- D. Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing a deployment from TEST to PROD requires careful handling of dependencies, especially when objects from another team's application are involved. The scenario describes a dependency issue during deployment, signaling a need for collaboration and governance. Let's evaluate each option:
A . Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD:
This approach involves duplicating the object, which introduces redundancy, maintenance risks, and potential version control issues. It violates Appian's governance principles, as objects should be owned and managed by their respective teams to ensure consistency and avoid conflicts. Appian's deployment best practices discourage duplicating objects unless absolutely necessary, making this an unsustainable and risky solution.
B . Halt the production deployment and contact the other team for guidance on promoting the object to PROD:
This is the correct step. When an object from another application (owned by a separate team) is a dependency, Appian's deployment process requires coordination to ensure both applications' objects are deployed in sync. Halting the deployment prevents partial deployments that could break functionality, and contacting the other team aligns with Appian's collaboration and governance guidelines. The other team can provide the necessary object version, adjust their deployment timeline, or resolve the dependency, ensuring a stable PROD environment.
C . Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk:
This approach risks deploying an incomplete or unstable application if the dependency isn't fully resolved. Even with "few dependencies" and "low risk," deploying without the other team's object could lead to runtime errors or broken functionality in PROD. Appian's documentation emphasizes thorough dependency management during deployment, requiring all objects (including those from other applications) to be promoted together, making this risky and not recommended.
D . Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints:
Deploying without dependencies creates an incomplete solution, potentially leaving the application non-functional or unstable in PROD. Appian's deployment process ensures all dependencies are included to maintain application integrity, and partial deployments are discouraged unless explicitly planned (e.g., phased rollouts). This option delays resolution and increases risk, contradicting Appian's best practices for Production stability.
Conclusion: Halting the production deployment and contacting the other team for guidance (B) is the next step. It ensures proper collaboration, aligns with Appian's governance model, and prevents deployment errors, providing a safe and effective resolution.
Appian Documentation: "Deployment Best Practices" (Managing Dependencies Across Applications).
Appian Lead Developer Certification: Application Management Module (Cross-Team Collaboration).
Appian Best Practices: "Handling Production Deployments" (Dependency Resolution).
NEW QUESTION # 22
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage Review the specs for four environments in the following image.
Which environment should you use for load testing7
- A. acmedev
- B. acmeuat
- C. acme
- D. acmetest
Answer: B
Explanation:
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2 acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8 acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat):This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
Option B (acmedev):The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme):The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest):The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
NEW QUESTION # 23
Your Appian project just went live with the following environment setup: DEV > TEST (SIT/UAT) > PROD. Your client is considering adding a support team to manage production defects and minor enhancements, while the original development team focuses on Phase 2. Your client is asking you for a new environment strategy that will have the least impact on Phase 2 development work. Which option involves the lowest additional server cost and the least code retrofit effort?
- A. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD
- B. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD
- C. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD
- D. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The goal is to design an environment strategy that minimizes additional server costs and code retrofit effort while allowing the support team to manage production defects and minor enhancements without disrupting the Phase 2 development team. The current setup (DEV > TEST (SIT/UAT) > PROD) uses a single development and testing pipeline, and the client wants to segregate support activities from Phase 2 development. Appian's Environment Management Best Practices emphasize scalability, cost efficiency, and minimal refactoring when adjusting environments.
Option C (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):
This option is the most cost-effective and requires the least code retrofit effort. It leverages the existing DEV environment for both teams but introduces a separate TEST2 environment for the support team's SIT/UAT activities. Since DEV is already shared, no new development server is needed, minimizing server costs. The existing code in DEV and TEST can be reused for TEST2 by exporting and importing packages, with minimal adjustments (e.g., updating environment-specific configurations). The Phase 2 team continues using the original TEST environment, avoiding disruption. Appian supports multiple test environments branching from a single DEV, and the PROD environment remains shared, aligning with the client's goal of low impact on Phase 2. The support team can handle defects and enhancements in TEST2 without interfering with development workflows.
Option A (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):
This introduces a STAGE environment for UAT in the Phase 2 stream, adding complexity and potentially requiring code updates to accommodate the new environment (e.g., adjusting deployment scripts). It also requires a new TEST2 server, increasing costs compared to Option C, where TEST2 reuses existing infrastructure.
Option B (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV2 > STAGE (SIT/UAT) > PROD):
This option adds both a DEV2 server for the support team and a STAGE environment, significantly increasing server costs. It also requires refactoring code to support two development environments (DEV and DEV2), including duplicating or synchronizing objects, which is more effort than reusing a single DEV.
Option D (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV2 > TEST (SIT/UAT) > PROD):
This introduces a DEV2 server for the support team, adding server costs. Sharing the TEST environment between teams could lead to conflicts (e.g., overwriting test data), potentially disrupting Phase 2 development. Code retrofit effort is higher due to managing two DEV environments and ensuring TEST compatibility.
Cost and Retrofit Analysis:
Server Cost: Option C avoids new DEV or STAGE servers, using only an additional TEST2, which can often be provisioned on existing hardware or cloud resources with minimal cost. Options A, B, and D require additional servers (TEST2, DEV2, or STAGE), increasing expenses.
Code Retrofit: Option C minimizes changes by reusing DEV and PROD, with TEST2 as a simple extension. Options A and B require updates for STAGE, and B and D involve managing multiple DEV environments, necessitating more significant refactoring.
Appian's recommendation for environment strategies in such scenarios is to maximize reuse of existing infrastructure and avoid unnecessary environment proliferation, making Option C the optimal choice.
NEW QUESTION # 24
You are reviewing log files that can be accessed in Appian to monitor and troubleshoot platform-based issues.
For each type of log file, match the corresponding Information that it provides. Each description will either be used once, or not at all.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.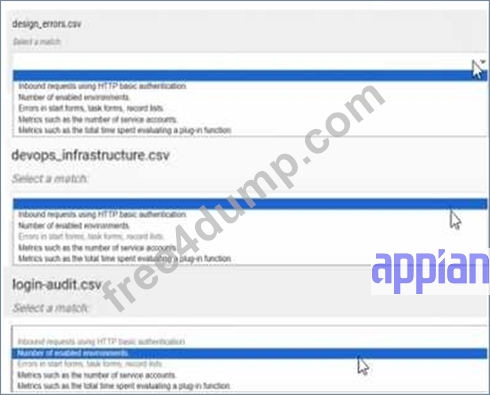
Answer:
Explanation: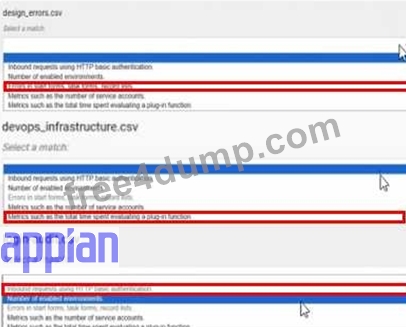
NEW QUESTION # 25
You are just starting with a new team that has been working together on an application for months. They ask you to review some of their views that have been degrading in performance. The views are highly complex with hundreds of lines of SQL. What is the first step in troubleshooting the degradation?
- A. Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed.
- B. Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge.
- C. Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance.
- D. Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Troubleshooting performance degradation in complex SQL views within an Appian application requires a systematic approach. The views, described as having hundreds of lines of SQL, suggest potential issues with query execution, indexing, or join efficiency. As a new team member, the first step should focus on quickly identifying the root cause without overhauling the system prematurely. Appian's Performance Troubleshooting Guide and database optimization best practices provide the framework for this process.
Option B (Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge):
This is the recommended first step. Running an EXPLAIN statement (or equivalent, such as EXPLAIN PLAN in some databases) analyzes the query execution plan, revealing details like full table scans, missing indices, or inefficient joins. This technical analysis can identify immediate optimization opportunities (e.g., adding indices or rewriting subqueries) without requiring business input, allowing you to address low-hanging fruit quickly. Appian encourages using database tools to diagnose performance issues before involving stakeholders, making this a practical starting point as you familiarize yourself with the application.
Option A (Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance):
This is too broad and time-consuming as a first step. Understanding business needs and normalizing tables are valuable but require collaboration with the team and stakeholders, delaying action. It's better suited for a later phase after initial technical analysis.
Option C (Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed):
Manually checking indices is useful but inefficient without first knowing which queries are problematic. The EXPLAIN statement provides targeted insights into index usage, making it a more direct initial step than a manual table-by-table review.
Option D (Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure):
Identifying null values and planning restructures is a long-term optimization strategy, not a first step. It requires team input and may not address the immediate performance degradation, which is better tackled with query-level diagnostics.
Starting with an EXPLAIN statement allows you to gather data-driven insights, align with Appian's performance troubleshooting methodology, and proceed with informed optimizations.
NEW QUESTION # 26
You are the project lead for an Appian project with a supportive product owner and complex business requirements involving a customer management system. Each week, you notice the product owner becoming more irritated and not devoting as much time to the project, resulting in tickets becoming delayed due to a lack of involvement. Which two types of meetings should you schedule to address this issue?
- A. A risk management meeting with your program manager to escalate the delayed tickets.
- B. An additional daily stand-up meeting to ensure you have more of the product owner's time.
- C. A meeting with the sponsor to discuss the product owner's performance and request a replacement.
- D. A sprint retrospective with the product owner and development team to discuss team performance.
Answer: A,D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing stakeholder engagement and ensuring smooth project progress are critical responsibilities. The scenario describes a product owner whose decreasing involvement is causing delays, which requires a proactive and collaborative approach rather than an immediate escalation to replacement. Let's analyze each option:
A . An additional daily stand-up meeting: While daily stand-ups are a core Agile practice to align the team, adding another one specifically to secure the product owner's time is inefficient. Appian's Agile methodology (aligned with Scrum) emphasizes that stand-ups are for the development team to coordinate, not to force stakeholder availability. The product owner's irritation might increase with additional meetings, making this less effective.
B . A risk management meeting with your program manager: This is a correct choice. Appian Lead Developer documentation highlights the importance of risk management in complex projects (e.g., customer management systems). Delays due to lack of product owner involvement constitute a project risk. Escalating this to the program manager ensures visibility and allows for strategic mitigation, such as resource reallocation or additional support, without directly confronting the product owner in a way that could damage the relationship. This aligns with Appian's project governance best practices.
C . A sprint retrospective with the product owner and development team: This is also a correct choice. The sprint retrospective, as per Appian's Agile guidelines, is a key ceremony to reflect on what's working and what isn't. Including the product owner fosters collaboration and provides a safe space to address their reduced involvement and its impact on ticket delays. It encourages team accountability and aligns with Appian's focus on continuous improvement in Agile development.
D . A meeting with the sponsor to discuss the product owner's performance and request a replacement: This is premature and not recommended as a first step. Appian's Lead Developer training emphasizes maintaining strong stakeholder relationships and resolving issues collaboratively before escalating to drastic measures like replacement. This option risks alienating the product owner and disrupting the project further, which contradicts Appian's stakeholder management principles.
Conclusion: The best approach combines B (risk management meeting) to address the immediate risk of delays with a higher-level escalation and C (sprint retrospective) to collaboratively resolve the product owner's engagement issues. These align with Appian's Agile and leadership strategies for Lead Developers.
Appian Lead Developer Certification: Agile Project Management Module (Risk Management and Stakeholder Engagement).
Appian Documentation: "Best Practices for Agile Development in Appian" (Sprint Retrospectives and Team Collaboration).
NEW QUESTION # 27
You are asked to design a case management system for a client. In addition to storing some basic metadata about a case, one of the client's requirements is the ability for users to update a case. The client would like any user in their organization of 500 people to be able to make these updates. The users are all based in the company's headquarters, and there will be frequent cases where users are attempting to edit the same case. The client wants to ensure no information is lost when these edits occur and does not want the solution to burden their process administrators with any additional effort. Which data locking approach should you recommend?
- A. Allow edits without locking the case CDI.
- B. Add an @Version annotation to the case CDT to manage the locking.
- C. Use the database to implement low-level pessimistic locking.
- D. Design a process report and query to determine who opened the edit form first.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The requirement involves a case management system where 500 users may simultaneously edit the same case, with a need to prevent data loss and minimize administrative overhead. Appian's data management and concurrency control strategies are critical here, especially when integrating with an underlying database.
Option C (Add an @Version annotation to the case CDT to manage the locking):
This is the recommended approach. In Appian, the @Version annotation on a Custom Data Type (CDT) enables optimistic locking, a lightweight concurrency control mechanism. When a user updates a case, Appian checks the version number of the CDT instance. If another user has modified it in the meantime, the update fails, prompting the user to refresh and reapply changes. This prevents data loss without requiring manual intervention by process administrators. Appian's Data Design Guide recommends @Version for scenarios with high concurrency (e.g., 500 users) and frequent edits, as it leverages the database's native versioning (e.g., in MySQL or PostgreSQL) and integrates seamlessly with Appian's process models. This aligns with the client's no-burden requirement.
Option A (Allow edits without locking the case CDI):
This is risky. Without locking, simultaneous edits could overwrite each other, leading to data loss-a direct violation of the client's requirement. Appian does not recommend this for collaborative environments.
Option B (Use the database to implement low-level pessimistic locking):
Pessimistic locking (e.g., using SELECT ... FOR UPDATE in MySQL) locks the record during the edit process, preventing other users from modifying it until the lock is released. While effective, it can lead to deadlocks or performance bottlenecks with 500 users, especially if edits are frequent. Additionally, managing this at the database level requires custom SQL and increases administrative effort (e.g., monitoring locks), which the client wants to avoid. Appian prefers higher-level solutions like @Version over low-level database locking.
Option D (Design a process report and query to determine who opened the edit form first):
This is impractical and inefficient. Building a custom report and query to track form opens adds complexity and administrative overhead. It doesn't inherently prevent data loss and relies on manual resolution, conflicting with the client's requirements.
The @Version annotation provides a robust, Appian-native solution that balances concurrency, data integrity, and ease of maintenance, making it the best fit.
NEW QUESTION # 28
You are reviewing the Engine Performance Logs in Production for a single application that has been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs. You also notice unattended process activities, including timer events and sending notification emails, are taking far longer to execute than normal.The client increased the number of CPU cores prior to the application going live.What is the next recommendation?
- A. Add more engine replicas.
- B. Add execution and analytics shards
- C. Add more application servers.
- D. Optimize slow-performing user interfaces.
Answer: A
Explanation:
As an Appian Lead Developer, analyzing Engine Performance Logs to address performance issues in a Production application requires understanding Appian's architecture and the specific metrics described. The scenario indicates a high "Work Queue - Java Work Queue Size," which reflects a backlog of tasks in the Java Work Queue (managed by Appian engines), and delays in unattended process activities (e.g., timer events, email notifications). These symptoms suggest the Appian engines are overloaded, despite the client increasing CPU cores. Let's evaluate each option:
A . Add more engine replicas:This is the correct recommendation. In Appian, engine replicas (part of the Appian Engine cluster) handle process execution, including unattended tasks like timers and notifications. A high Java Work Queue Size indicates the engines are overwhelmed by concurrent activity during business hours, causing delays. Adding more engine replicas distributes the workload, reducing queue size and improving performance for both user-driven and unattended tasks. Appian's documentation recommends scaling engine replicas to handle sustained loads, especially in Production with high concurrency. Since CPU cores were already increased (likely on application servers), the bottleneck is likely the engine capacity, not the servers.
B . Optimize slow-performing user interfaces:While optimizing user interfaces (e.g., SAIL forms, reports) can improve user experience, the scenario highlights delays in unattended activities (timers, emails), not UI performance. The Java Work Queue Size issue points to engine-level processing, not UI rendering, so this doesn't address the root cause. Appian's performance tuning guidelines prioritize engine scaling for queue-related issues, making this a secondary concern.
C . Add more application servers:Application servers handle web traffic (e.g., SAIL interfaces, API calls), not process execution or unattended tasks managed by engines. Increasing application servers would help with UI concurrency but wouldn't reduce the Java Work Queue Size or speed up timer/email processing, as these are engine responsibilities. Since the client already increased CPU cores (likely on application servers), this is redundant and unrelated to the issue.
D . Add execution and analytics shards:Execution shards (for process data) and analytics shards (for reporting) are part of Appian's data fabric for scalability, but they don't directly address engine workload or Java Work Queue Size. Shards optimize data storage and query performance, not real-time process execution. The logs indicate an engine bottleneck, not a data storage issue, so this isn't relevant. Appian's documentation confirms shards are for long-term scaling, not immediate performance fixes.
Conclusion: Adding more engine replicas (A) is the next recommendation. It directly resolves the high Java Work Queue Size and delays in unattended tasks, aligning with Appian's architecture for handling concurrent loads in Production. This requires collaboration with system administrators to configure additional replicas in the Appian cluster.
Appian Documentation: "Engine Performance Monitoring" (Java Work Queue and Scaling Replicas).
Appian Lead Developer Certification: Performance Optimization Module (Engine Scaling Strategies).
Appian Best Practices: "Managing Production Performance" (Work Queue Analysis).
NEW QUESTION # 29
You have created a Web API in Appian with the following URL to call it: https://exampleappiancloud.com/suite/webapi/user_management/users?username=john.smith. Which is the correct syntax for referring to the username parameter?
- A. httpRequest.users.username
- B. httpRequest.queryParameters.username
- C. httpRequest.queryParameters.users.username
- D. httpRequest.formData.username
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
In Appian, when creating a Web API, parameters passed in the URL (e.g., query parameters) are accessed within the Web API expression using the httpRequest object. The URL https://exampleappiancloud.com/suite/webapi/user_management/users?username=john.smith includes a query parameter username with the value john.smith. Appian's Web API documentation specifies how to handle such parameters in the expression rule associated with the Web API.
Option D (httpRequest.queryParameters.username):
This is the correct syntax. The httpRequest.queryParameters object contains all query parameters from the URL. Since username is a single query parameter, you access it directly as httpRequest.queryParameters.username. This returns the value john.smith as a text string, which can then be used in the Web API logic (e.g., to query a user record). Appian's expression language treats query parameters as key-value pairs under queryParameters, making this the standard approach.
Option A (httpRequest.queryParameters.users.username):
This is incorrect. The users part suggests a nested structure (e.g., users as a parameter containing a username subfield), which does not match the URL. The URL only defines username as a top-level query parameter, not a nested object.
Option B (httpRequest.users.username):
This is invalid. The httpRequest object does not have a direct users property. Query parameters are accessed via queryParameters, and there's no indication of a users object in the URL or Appian's Web API model.
Option C (httpRequest.formData.username):
This is incorrect. The httpRequest.formData object is used for parameters passed in the body of a POST or PUT request (e.g., form submissions), not for query parameters in a GET request URL. Since the username is part of the query string (?username=john.smith), formData does not apply.
The correct syntax leverages Appian's standard handling of query parameters, ensuring the Web API can process the username value effectively.
NEW QUESTION # 30
Users must be able to navigate throughout the application while maintaining complete visibility in the application structure and easily navigate to previous locations. Which Appian Interface Pattern would you recommend?
- A. Use Billboards as Cards pattern on the homepage to prominently display application choices.
- B. Implement a Drilldown Report pattern to show detailed information about report data.
- C. Include a Breadcrumbs pattern on applicable interfaces to show the organizational hierarchy.
- D. Implement an Activity History pattern to track an organization's activity measures.
Answer: C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The requirement emphasizes navigation with complete visibility of the application structure and the ability to return to previous locations easily. The Breadcrumbs pattern is specifically designed to meet this need. According to Appian's design best practices, the Breadcrumbs pattern provides a visual trail of the user's navigation path, showing the hierarchy of pages or sections within the application. This allows users to understand their current location relative to the overall structure and quickly navigate back to previous levels by clicking on the breadcrumb links.
Option A (Billboards as Cards): This pattern is useful for presenting high-level options or choices on a homepage in a visually appealing way. However, it does not address navigation visibility or the ability to return to previous locations, making it irrelevant to the requirement.
Option B (Activity History): This pattern tracks and displays a log of activities or actions within the application, typically for auditing or monitoring purposes. It does not enhance navigation or provide visibility into the application structure.
Option C (Drilldown Report): This pattern allows users to explore detailed data within reports by drilling into specific records. While it supports navigation within data, it is not designed for general application navigation or maintaining structural visibility.
Option D (Breadcrumbs): This is the correct choice as it directly aligns with the requirement. Per Appian's Interface Patterns documentation, Breadcrumbs improve usability by showing a hierarchical path (e.g., Home > Section > Subsection) and enabling backtracking, fulfilling both visibility and navigation needs.
NEW QUESTION # 31
Your Agile Scrum project requires you to manage two teams, with three developers per team. Both teams are to work on the same application in parallel. How should the work be divided between the teams, avoiding issues caused by cross-dependency?
- A. Group epics and stories by feature, and allocate work between each team by feature.
- B. Have each team choose the stories they would like to work on based on personal preference.
- C. Group epics and stories by technical difficulty, and allocate one team the more challenging stories.
- D. Allocate stories to each team based on the cumulative years of experience of the team members.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
In an Agile Scrum environment with two teams working on the same application in parallel, effective work division is critical to avoid cross-dependency, which can lead to delays, conflicts, and inefficiencies. Appian's Agile Development Best Practices emphasize team autonomy and minimizing dependencies to ensure smooth progress.
Option B (Group epics and stories by feature, and allocate work between each team by feature):
This is the recommended approach. By dividing the application's functionality into distinct features (e.g., Team 1 handles customer management, Team 2 handles campaign tracking), each team can work independently on a specific domain. This reduces cross-dependency because teams are not reliant on each other's deliverables within a sprint. Appian's guidance on multi-team projects suggests feature-based partitioning as a best practice, allowing teams to own their backlog items, design, and testing without frequent coordination. For example, Team 1 can develop and test customer-related interfaces while Team 2 works on campaign processes, merging their work during integration phases.
Option A (Group epics and stories by technical difficulty, and allocate one team the more challenging stories):
This creates an imbalance, potentially overloading one team and underutilizing the other, which can lead to morale issues and uneven progress. It also doesn't address cross-dependency, as challenging stories might still require input from both teams (e.g., shared data models), increasing coordination needs.
Option C (Allocate stories to each team based on the cumulative years of experience of the team members):
Experience-based allocation ignores the project's functional structure and can result in mismatched skills for specific features. It also risks dependencies if experienced team members are needed across teams, complicating parallel work.
Option D (Have each team choose the stories they would like to work on based on personal preference):
This lacks structure and could lead to overlap, duplication, or neglect of critical features. It increases the risk of cross-dependency as teams might select interdependent stories without coordination, undermining parallel development.
Feature-based division aligns with Scrum principles of self-organization and minimizes dependencies, making it the most effective strategy for this scenario.
NEW QUESTION # 32
......
ACD-301 Study Material, Preparation Guide and PDF Download: https://www.free4dump.com/ACD-301-braindumps-torrent.html
ACD-301 Actual Questions 100% Same Braindumps with Actual Exam: https://drive.google.com/open?id=12qBQy_4-7uCMOxH4i9VEVuSB64z5j7vL